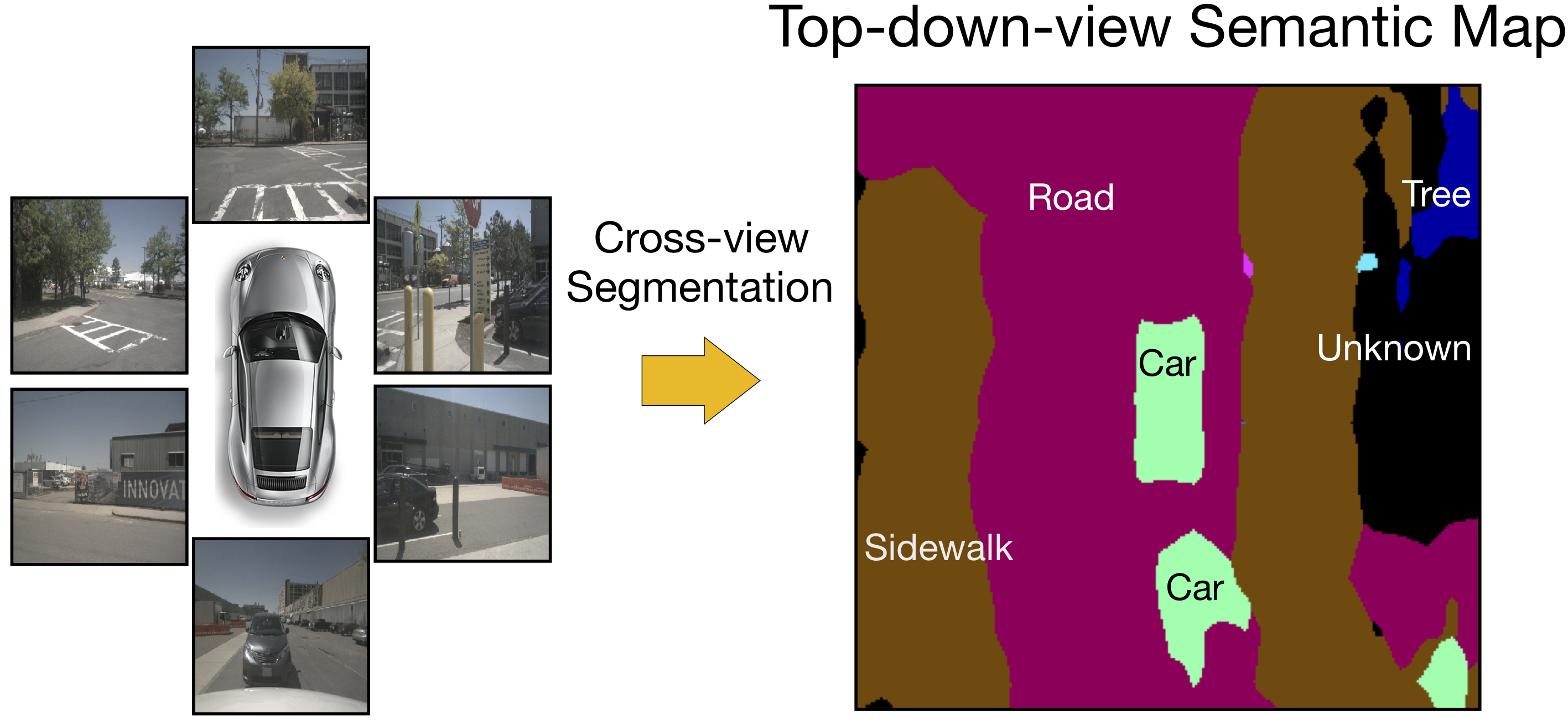
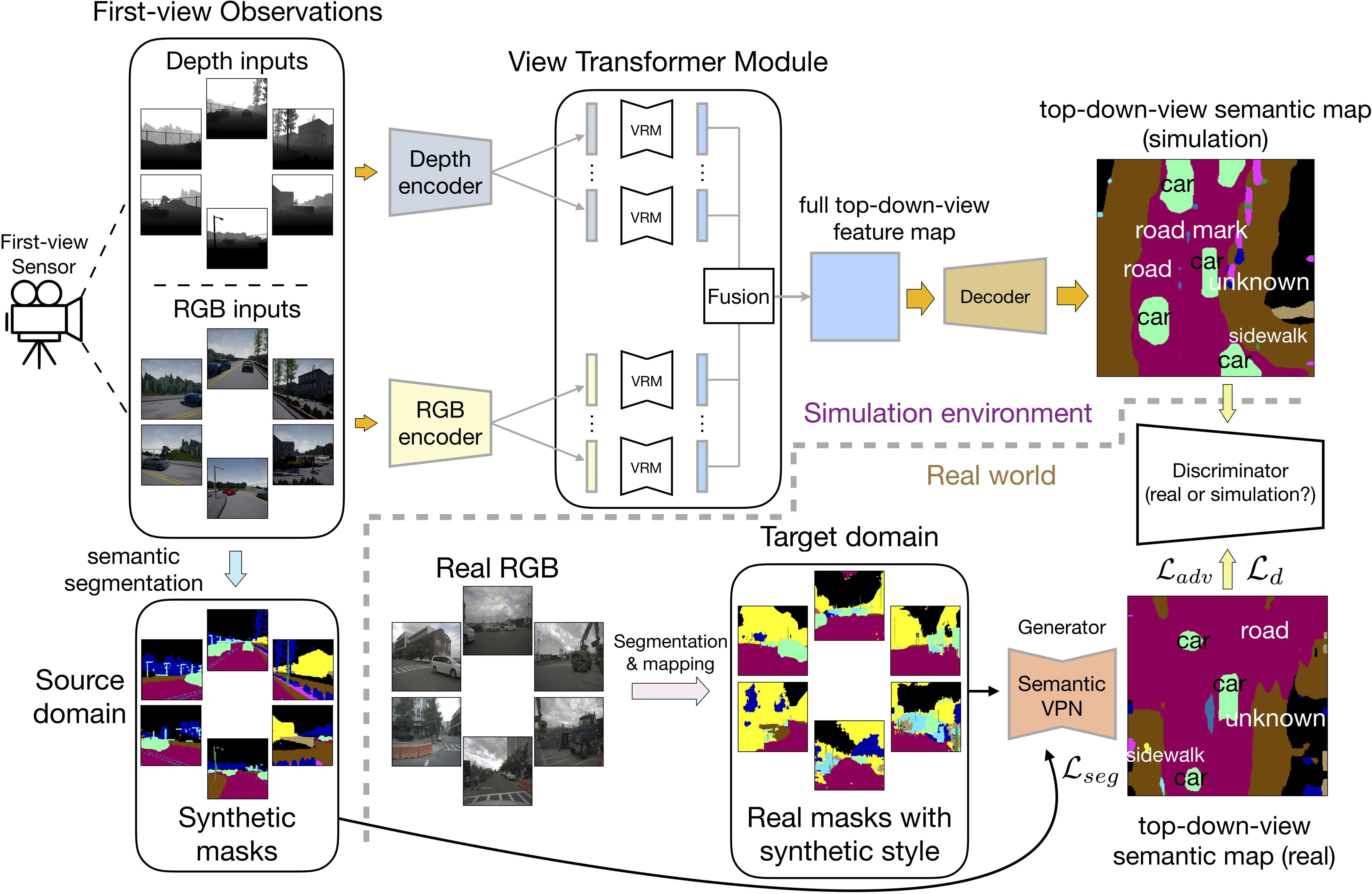
We introduce a novel spatial understanding task calls Cross-view Semantic Segmentation. In this task, top-down-view semantics are predicted from the first-view real-world observations. Input observations from multiple angles are fused together.
Cross-view Semantic Segmentation for Sensing Surroundings |
||
Bowen Pan1, Jiankai Sun2, Ho Yin Tiga Leung2, Alex Andonian1, Bolei Zhou2 |
||
1 Massachusetts Institute of Technology |
||
2 The Chinese University of Hong Kong |
||
[Paper] [Code] [Supplemental Materials] [1-min Demo Video] |
||